Semantic versioning is a core pillar of responsible open source publishing. It offers a clear mechanism for communicating compatibility betweeen versions and downstream tools can act on the reported compatibility.
While the major.minor.patch scheme is extremely clear, agreement and adherence to the rules for increasing each number varies wildly across the open-source ecosystem.
What happens when the published semver is wrong? Tools will make incorrect assumptions that might break your app if you're not paying careful attention. These issues can be insidious because they may only show up under sporadic conditions.
Using Resemver - Re(write) Semver
We set out to measure semver accuracy with a tool called resemver, which uses AI to find breaking changes and new features in an NPM package and cumulatively rewrite the semantic versions accordingly.
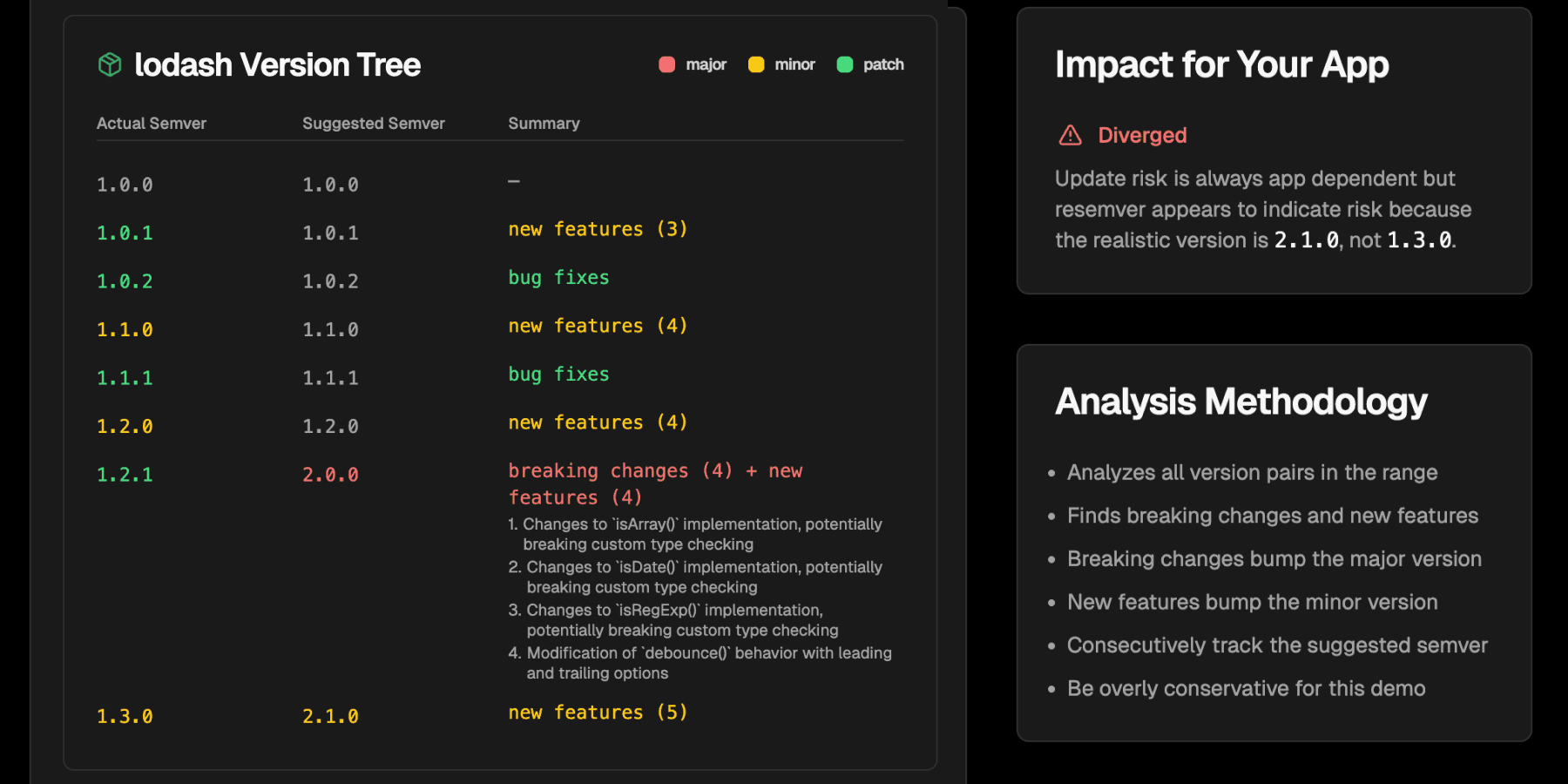
| Resemver analysis of lodash v1.0.0 → v1.3.0 | ||
|---|---|---|
| Actual Semver | Suggested Semver | Summary |
| 1.0.0 | 1.0.0 | — |
| 1.0.1 | 1.0.1 | new features (3) |
| 1.0.2 | 1.0.2 | bug fixes |
| 1.1.0 | 1.1.0 | new features (4) |
| 1.1.1 | 1.1.1 | bug fixes |
| 1.2.0 | 1.2.0 | new features (4) |
| 1.2.1 | 2.0.0 | breaking changes (4) + new features (4) |
| 1.3.0 | 2.1.0 | new features (5) |
The last line of this table shows that between these two versions of lodash, the published semver reached 1.3.0 but based on the behaviors changed in those versions, it should actually be published under 2.1.0. See the full report here to follow along.
This was mainly caused by a set of 4 breaking changes in 1.2.1:
- Changes to
isArray()implementation, potentially breaking custom type checking- Changes to
isDate()implementation, potentially breaking custom type checking- Changes to
isRegExp()implementation, potentially breaking custom type checking- Modification of
debounce()behavior with leading and trailing options
We're looking at a very old package for demo purposes, but you can run your own analysis of a package you frequently use.
What Happens When Semver Is Used Incorrectly?
In short, tools will make incorrect assumptions that might break your app if you're not careful.
In our example above, npm will incorrectly assume upgrading between these versions contains no breaking changes.
An update tool like Dependabot might assign a much lower probability of breakage or allow this upgrade under a "minors-only" policy even though it actually has a big breaking change.
That leads to more noise for engineers and increasing distrust of the upgrade process.
How Does This Impact Your App?
Researching all of the changes in a package to verify compatibility and find breaking changes is a great method to "trust but verify" that semver was done correctly.
What really matters, however, is the impact to your app based on how you use each dependency. If you can detect this accurately, you can throw out semver altogether and focus on quickly merging safe upgrades no matter how large the version jump. Then, focus attention on the specific issue or usage that is detected to cause a problem.
As you can see, this is a very powerful way to run an upgrade program. It scales well because engineers are focused on the tricky upgrades without any of the research toil it takes to find app breakage.
This is an area that FOSSA is very interested in – stay tuned for more.